Prometheus, Grafana, Loki로 모니터링 구성하기 (홈랩 k8s 구축기 5편)

지난 편에서 CI/CD 파이프라인을 구성했다. 이번 편은 모니터링이다. 클러스터가 잘 돌아가고 있는지, 어디서 문제가 생겼는지 파악하려면 메트릭과 로그를 봐야 한다. 그리고 이번 편에서는 삽질이 꽤 많았다.
스택 구성
모니터링 스택은 세 가지로 구성했다.
| 역할 | 도구 |
|---|---|
| 메트릭 수집 / 시각화 | Prometheus + Grafana (kube-prometheus-stack) |
| 로그 저장 | Loki |
| 로그 수집 에이전트 | Grafana Alloy |
kube-prometheus-stack은 Prometheus, Grafana, AlertManager, node-exporter, kube-state-metrics를 한 번에 설치해준다. 직접 하나씩 구성하는 것보다 훨씬 편하고, ServiceMonitor 같은 CRD도 함께 설치된다.
Prometheus targets가 전부 DOWN
설치 후 Grafana에 들어가봤더니 대시보드 패널들이 대부분 비어있었다. Prometheus 대시보드에서 targets를 확인해보니 kube-controller-manager, kube-scheduler, etcd, kube-proxy가 전부 DOWN이었다.
원인을 찾아보니 kubeadm의 기본 설정 문제였다. 이 컴포넌트들이 기본적으로 127.0.0.1에만 바인딩된다. Prometheus는 Pod IP로 메트릭 엔드포인트에 접근하는데, 로컬호스트에만 열려있으니 당연히 접근이 안 됐던 것이다.
운영 중인 클러스터라 Control Plane VM에 직접 들어가서 매니페스트를 수정했다.
ssh ubuntu@192.168.50.110
sudo sed -i 's/--bind-address=127.0.0.1/--bind-address=0.0.0.0/' \
/etc/kubernetes/manifests/kube-controller-manager.yaml
sudo sed -i 's/--bind-address=127.0.0.1/--bind-address=0.0.0.0/' \
/etc/kubernetes/manifests/kube-scheduler.yaml
sudo sed -i 's|--listen-metrics-urls=http://127.0.0.1:2381|--listen-metrics-urls=http://0.0.0.0:2381|' \
/etc/kubernetes/manifests/etcd.yamlkube-proxy는 ConfigMap을 수정하고 재시작했다.
수정 후 targets가 모두 UP으로 바뀌었다. 이 문제는 나중에 Ansible kubeadm config 파일에 반영해두었다. 다음에 클러스터를 재구성할 때는 처음부터 올바르게 설정된 채로 올라온다.
Longhorn 대시보드 패널이 비어있음
Prometheus targets 문제를 해결하고 나서도 Longhorn 대시보드 패널이 계속 비어있었다. 이번에는 다른 이유였다.
kube-prometheus-stack은 기본적으로 release: kube-prometheus-stack 라벨이 붙은 ServiceMonitor만 수집한다. Longhorn이 설치 시 만들어주는 ServiceMonitor에 그 라벨이 없었던 것이다. Prometheus는 Longhorn이 있는지조차 몰랐던 셈이다.
해결은 Longhorn Helm values에 라벨을 추가하는 것이었다.
metrics:
serviceMonitor:
enabled: true
additionalLabels:
release: kube-prometheus-stack적용 후 Longhorn 대시보드가 정상적으로 채워졌다.
Grafana 대시보드 Import
kube-prometheus-stack이 기본으로 제공하는 대시보드 외에 두 개를 추가했다. Node Exporter Full(ID: 1860)과 Longhorn(ID: 16888)이다. Grafana에서 ID로 Import하면 되는데, 여기서 또 한 가지 문제가 생겼다.
클러스터 안에서 외부 인터넷 접근이 막혀있어서 Grafana Pod이 대시보드 JSON을 직접 받아오지 못했다. 로컬 PC에서 JSON을 다운로드하고, 파일 업로드 방식으로 Import했다.
curl -o node-exporter-full.json \
https://grafana.com/api/dashboards/1860/revisions/latest/download이후 Grafana → Dashboards → Import → “Upload dashboard JSON file”로 업로드했다. 번거롭긴 했지만 한 번만 하면 된다.
Loki + Alloy
로그 수집은 Loki와 Grafana Alloy로 구성했다. Alloy는 Promtail의 후속으로, 각 노드에 DaemonSet으로 배포되어 Pod 로그를 수집해서 Loki로 전송한다.
Loki를 설치하면서 retention 설정을 추가했는데, 처음에 설정이 잘못되어 CrashLoopBackOff가 났다. retention_enabled: true를 추가할 때 delete_request_store를 함께 설정해야 하는데 그걸 빠뜨렸던 것이다.
loki:
limits_config:
retention_period: 15d
compactor:
retention_enabled: true
working_directory: /var/loki/compactor
delete_request_store: filesystem # ← 이게 없으면 시작을 못 한다Alloy에서는 시스템 네임스페이스 로그를 수집에서 제외했다. kube-system, longhorn-system, monitoring 같은 네임스페이스는 로그 양이 많지만 직접 운영하는 서비스가 아니라서 Loki에 쌓을 필요가 없다. 필요할 때는 kubectl logs로 직접 보면 된다. ingress-nginx는 이상한 트래픽이 들어오는지 확인하기 위해 수집 대상으로 남겨뒀다.
데이터 보존 정책
Prometheus는 메트릭 데이터가 계속 쌓이면 디스크를 많이 차지하게 된다. 적절한 보존 기간과 크기 제한을 설정해두었다.
| 항목 | 설정 |
|---|---|
| Prometheus 보존 기간 | 15일 |
| Prometheus 최대 크기 | 18GB (PVC 20Gi 기준) |
| Loki 보존 기간 | 15일 |
여기까지 오면
Prometheus, Grafana, Loki가 정상 동작하면 클러스터와 서비스의 상태를 한눈에 볼 수 있다. 노드 CPU, 메모리, 디스크 사용량, Pod별 자원 사용량, 로그까지 Grafana 한 곳에서 확인할 수 있다.
다음 편에서는 보안 강화와 외부 접근 설정을 이야기 하겠다.
이 저작물은 크리에이티브 커먼즈 저작자표시-비영리-동일조건변경허락 4.0 국제 라이선스 에 따라 이용할 수 있습니다.
Comments
Related Posts
집에 Kubernetes 클러스터를 구축해 봤습니다
퇴근하고 집에 돌아와 미니 PC 한 대를 책상 위에 올려두고는 여기다가 Kubernetes 클러스터를 직접 구축해 보겠다고 마음먹은 게 몇 달 전이었다. 그리고 지금, 그 미니 P…
보안 강화와 Tailscale VPN으로 외부 접근 설정하기 (홈랩 k8s 구축기 6편)
지난 편에서 모니터링 스택을 올렸다. 이번 편은 마지막으로, 보안 강화와 외부 접근 설정이다. 보안을 신경 쓰는 이유 홈랩이라고 해도 실제 서비스를 운영하려면 보안을 무시할 수 없…
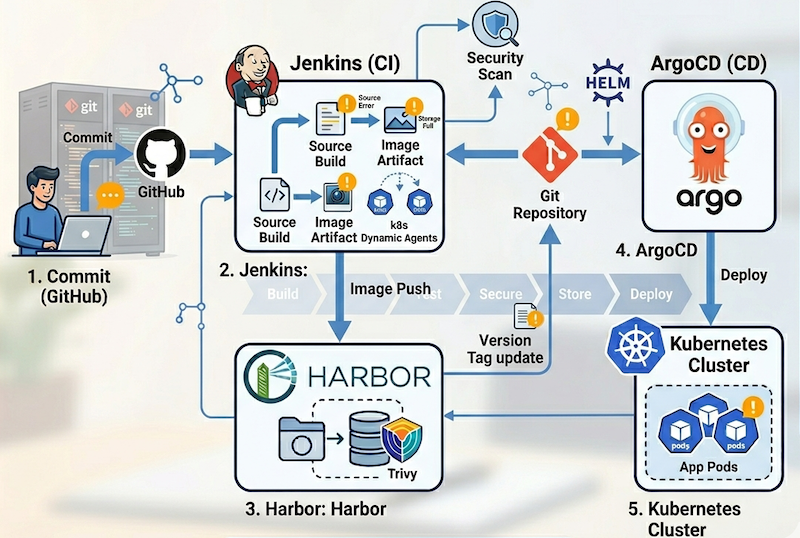
Jenkins, ArgoCD, Harbor로 CI/CD 파이프라인 구성하기 (홈랩 k8s 구축기 4편)
지난 편에서 네트워크와 스토리지를 구성했다. 이번에는 코드를 빌드하고 클러스터에 배포하는 파이프라인을 만드는 차례다. CI/CD를 왜 직접 구성하는가 GitHub Actions를…