MongoDb Cloud Atlas DataLake 란 무엇인가?
2019년 하반기에 MongoDb DataLake 와 AWS Kinesis로 작업을 하면서 정리 한 내용을 기록 한다.
몽고 DB Data Lake 란
AWS S3 데이터를 Atlas 클러스트를 통해 빠르게 쿼리 할 수 있는 서비스
Mongo Shell, MongoDb Compass, MongoDb 드라이버를 이용하여 몽고 DB를 사용 하는 것 처럼 사용 할 수 있음
Data Lake 가 지원하는 데이터 포멧
- Apache Avro
- Parquet
- JOSN
- JSON/Gzipped
- BSON
- CSV(헤더 필수)
- TSV(헤더 필수)
비용
- S3 버킷에서 스캔한 총 바이트 수를 가장 가까운 메가 바이트로 올림하여 청구
- 스캔한 데이터의 TB당 $5.00
- 쿼리당 최소 10MB 또는 $0.00005
- 데이터 전송비용
- https://docs.atlas.mongodb.com/billing/#data-lake-billing
접속하기
- 일반 몽고DB 접속과 동일한 방법으로 하면 된다.
- Atlas 에서 데이터베이스 엑세스를 위해 생성한 유저 ID를 이용 하면 된다.
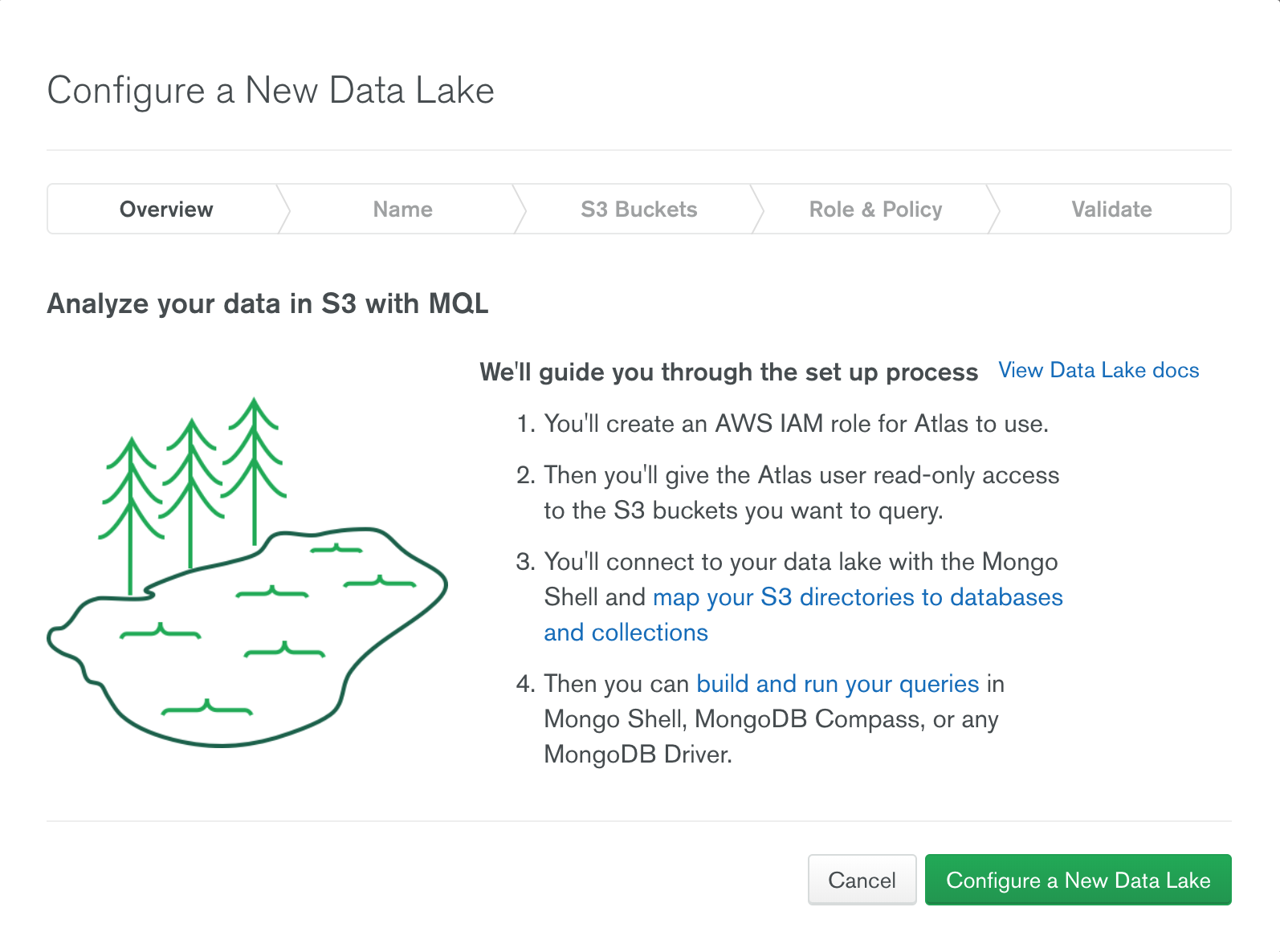
Data Lake 생성하기
Data Lake란, MongoDb 쿼리 언어를 사용하여 저렴한 S3 버킷에 저장된 데이터를 쿼리 하기 위한 MongoDb 솔루션
-
S3 버킷 생성
- S3에 버킷을 생성하고(리전은 상관 없음) 쿼리 할 데이터를 업로드 한다.
-
Data Lake 추가
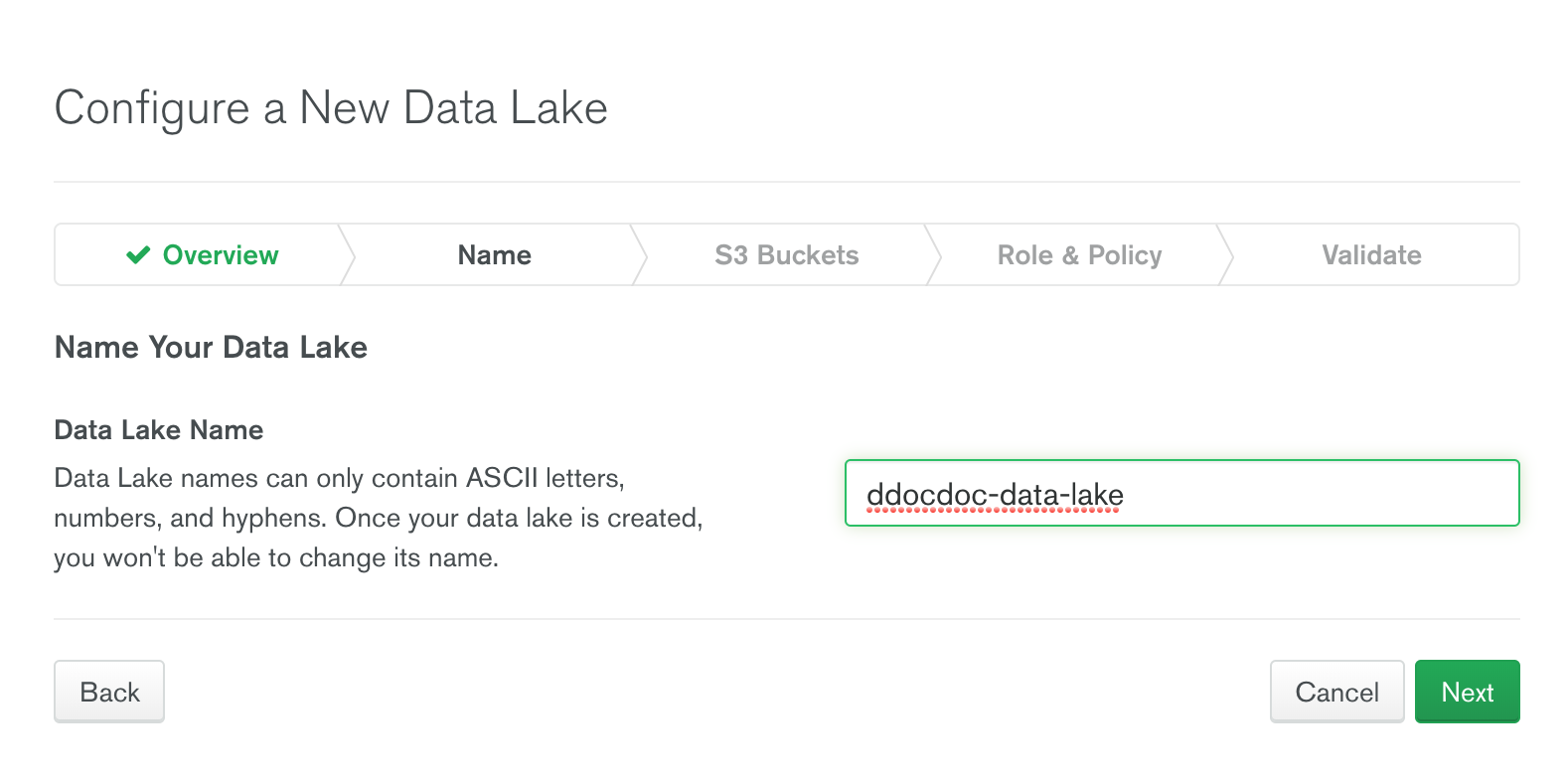
- DataLake 이름을 지정 한다.
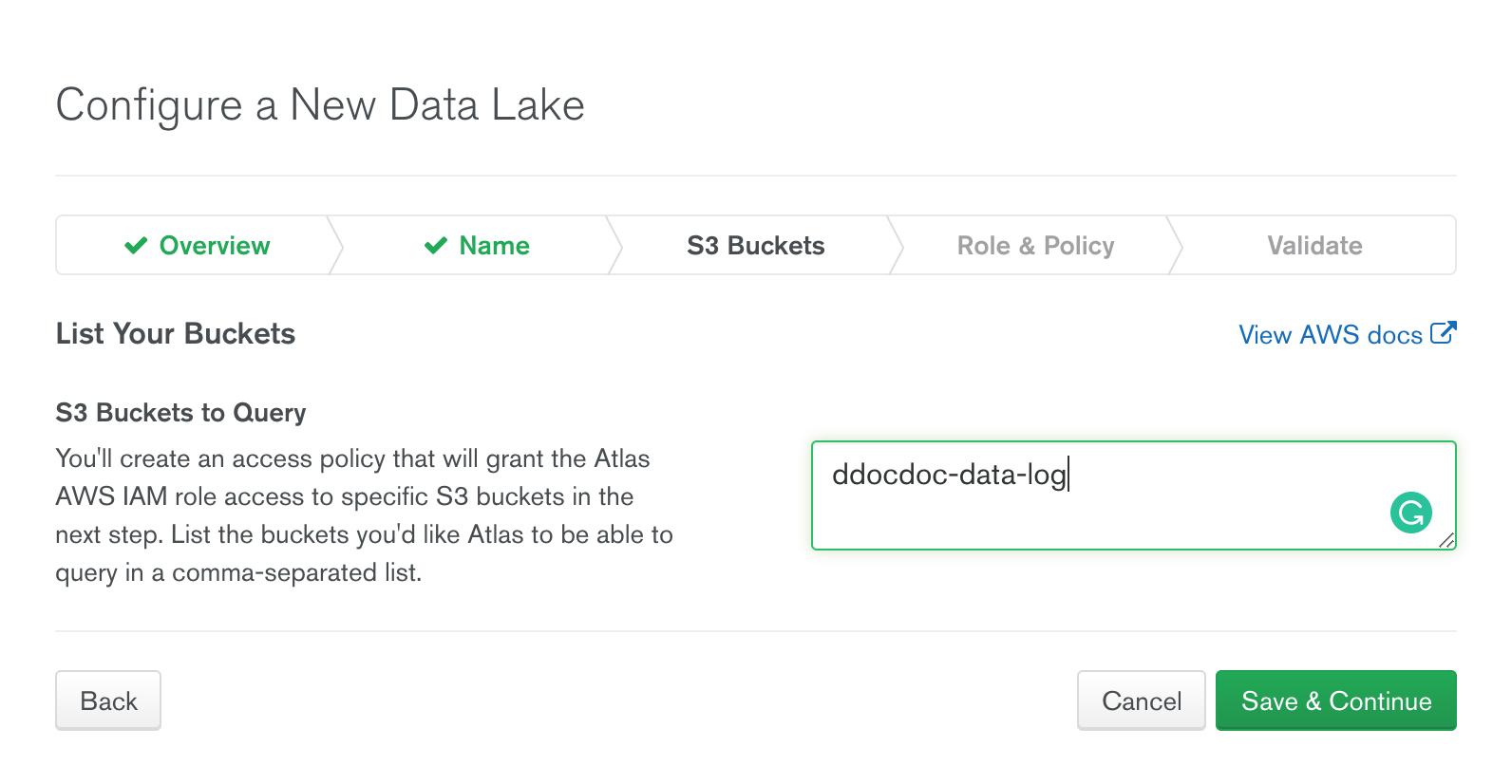
- 사용할 버킷이름을 입력 한다.
- 하나의 Data Lake 에서 여러개의 버킷을 지정 할 수 있으며, 여러개의 버킷을 지정할 때는 콤마(,)로 구분한다.
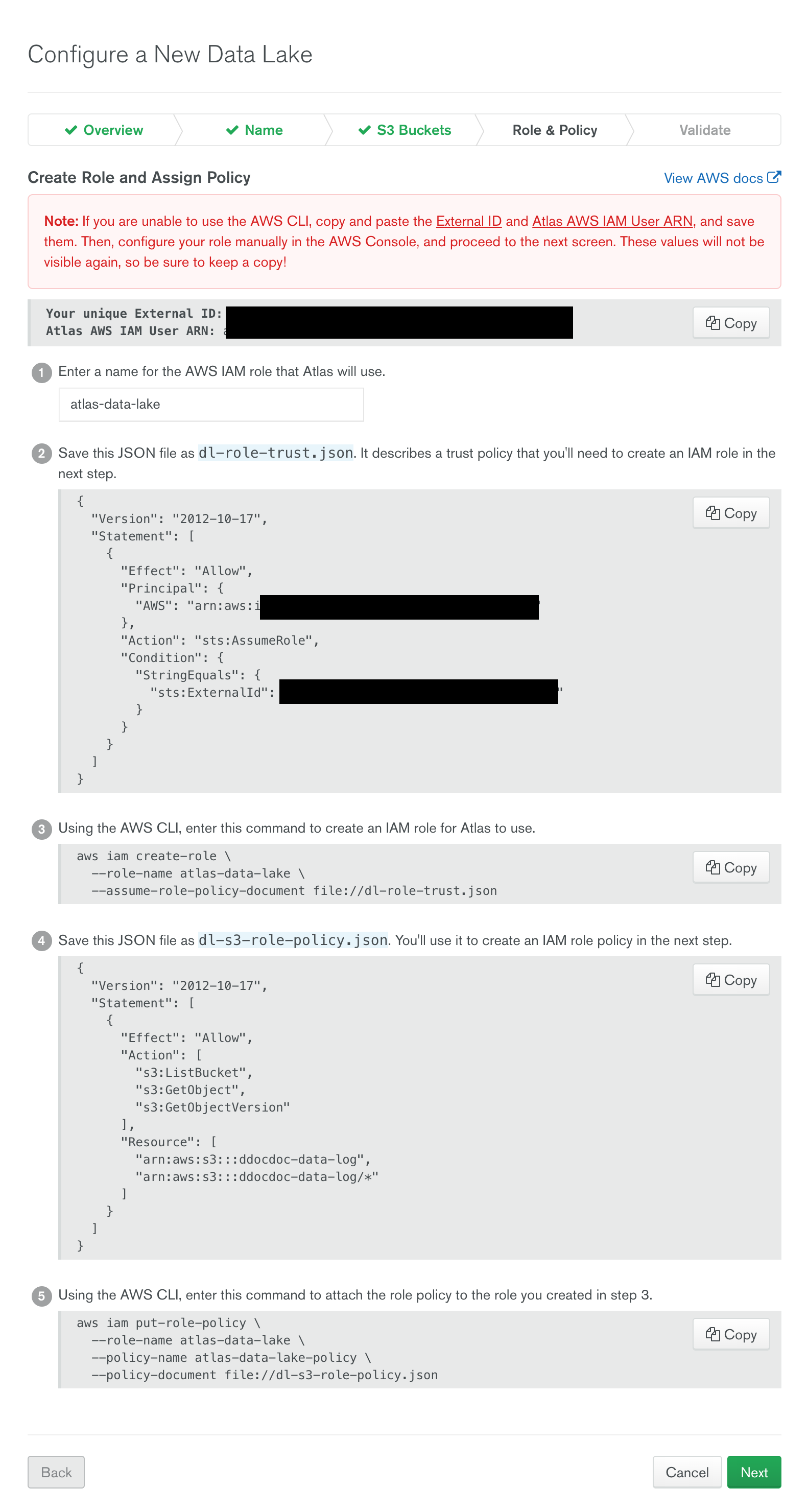
- AWS IAM Role을 생성한다.
- CLI를 이용해서 예시나 나온대로 명령어를 입력 하거나, AWS Console을 통해 Role 과 Policy를 생성한다.
- 이 화면에서 나오는 External ID와 Atlas AWS IAM User ARN은 매우 중요한 데이터 이며, 반드시 복사 하여 다른곳에 저장한다. 화면을 닫을 경우 다시 확인 할 수 없다.
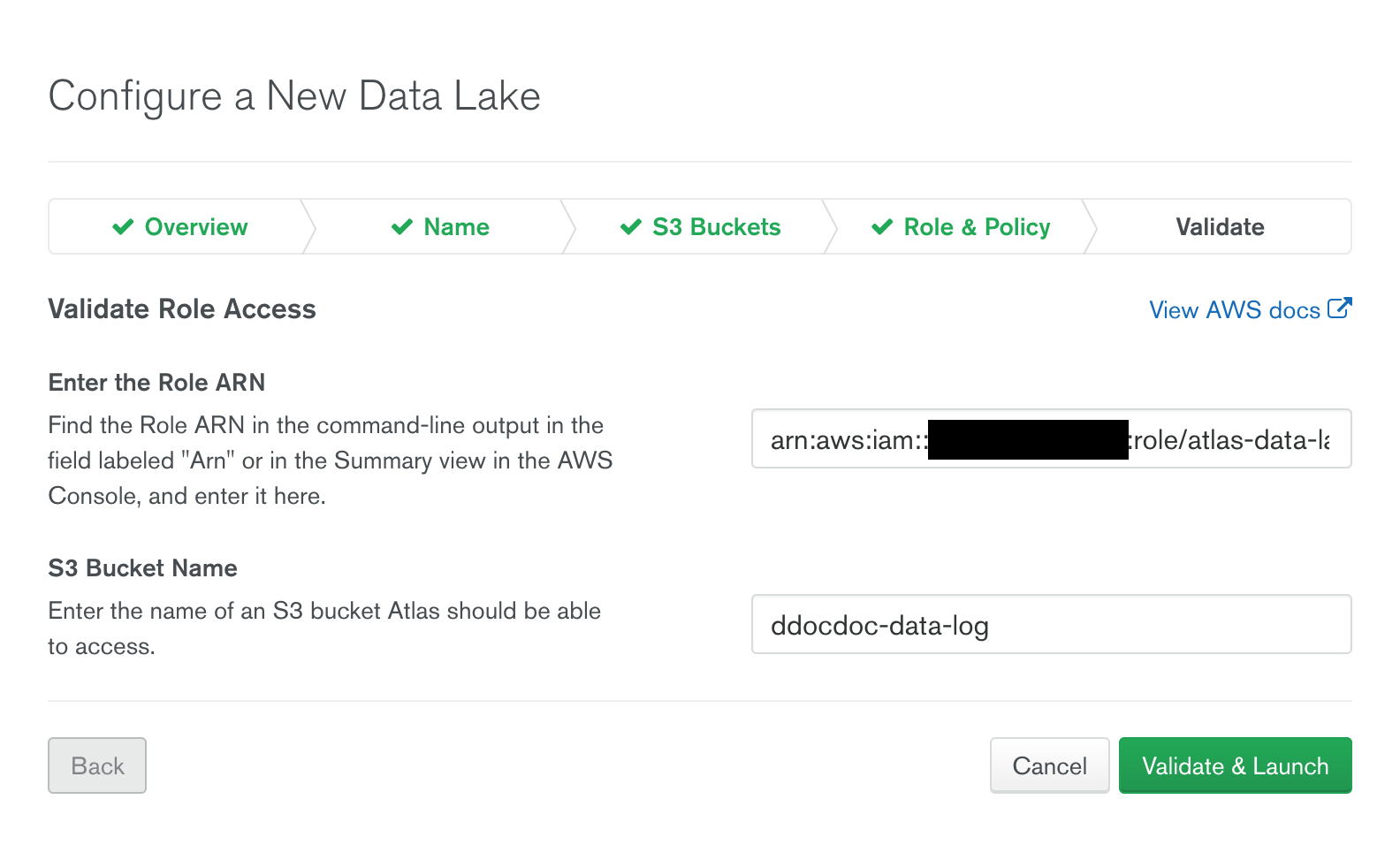
- 이전 단계에서 생성한 Role 의 ARN 을 입력 한다.
- CLI를 이용한 경우 Role 생성 후 출력된 결과에서 확인 할 수 있다.
- DataLake 이름을 지정 한다.
-
Data Lake 접속하기
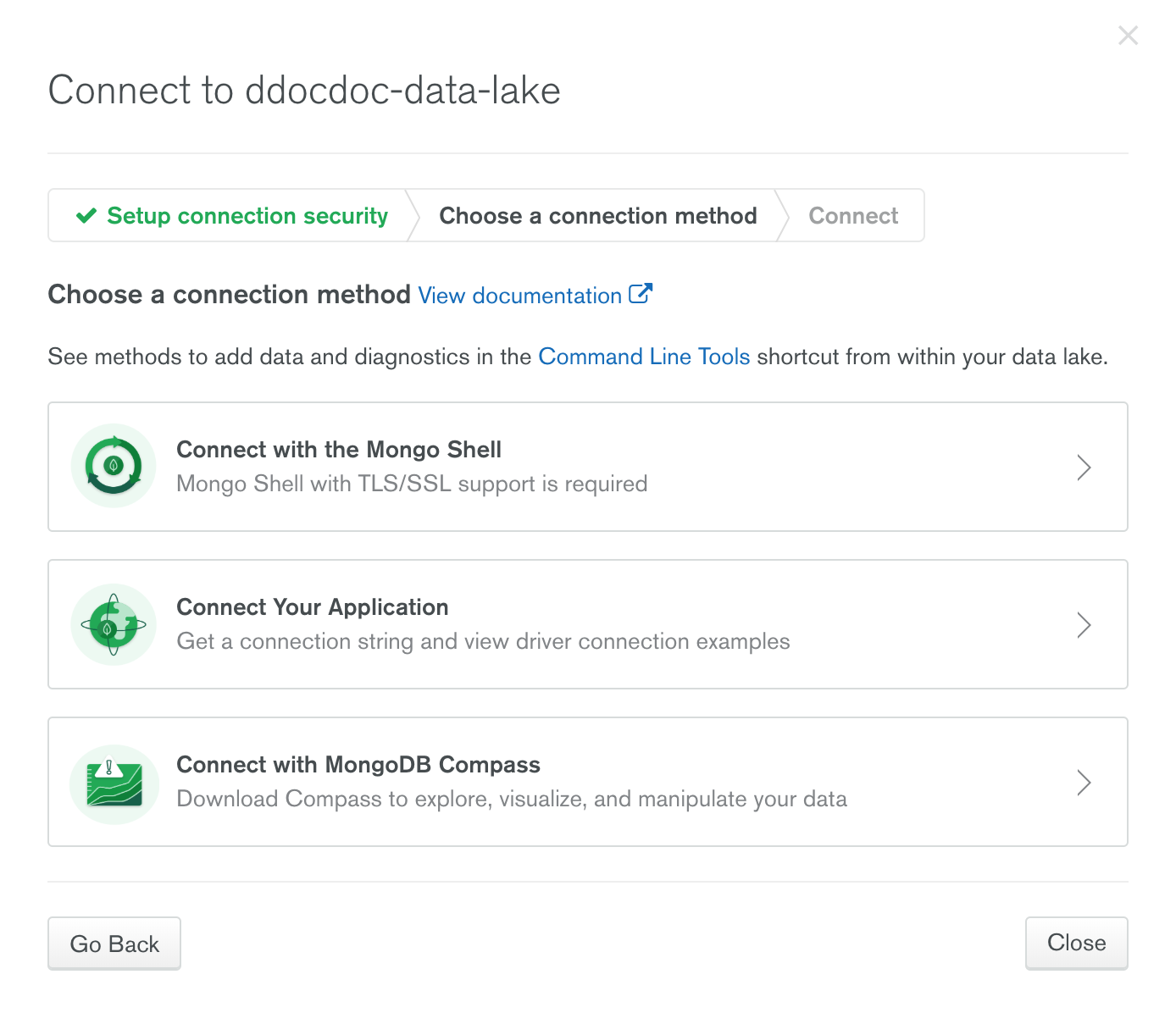
- 원하는 접속 방식을 선택하고 URL을 획득하여, Altas 에서 생성한 유저를 이용하여 접속 한다.
-
데이터 베이스 설정하기
- 버킷 리전과, 버킷명을 입력하여 데이터 베이스를 설정한다.
use admin; db.runCommand( { "storageSetConfig": { "stores": [{ "s3": { "name": "s3store", // Creates an S3 store "region":"<bucket-region>", // Update with the bucket region code "bucket": "<bucket-name>" // Update with your bucket name } }], "databases": { "sample": { // Creates a database named sample "*": [{ /* Works with the defintion to create a collection the data in each directory */ "store": "s3store", // Links to the S3 store above "definition": "/json/{collectionName()}" }] } } }})
이 저작물은 크리에이티브 커먼즈 저작자표시-비영리-동일조건변경허락 4.0 국제 라이선스 에 따라 이용할 수 있습니다.
Comments
Related Posts

MongoDB Data Lake 설정 하기
AWS S3 와 Atlas Data Lake 간의 매핑의 정의 MongoDb의 Database 와 Collection 처럼 사용하기 위하여 데이터가 저장된 위치 및 데이터 파일에…

AWS S3의 Cross Domain 해결을 위한 CORS 사용
를 통하여 서로 다른 도메인 간에 통신을 해야 하는 경우 브라우저의 보안 정책으로 인하여 통신이 불가능하다. 이런 경우 를 통하여 이를 해결할 수 있다. 가 무엇인지에 대한 자세한…
AWS에서 NFS 서버 세팅
서버로 사용할 인스턴스 생성 Security Group 설정에서 Type을 All traffic 선택 Source를 172.31.0.0/16 입력 172.31.0.0/16 은 서버…