GraphQL Mutation에서 DataLoader를 사용해도 될까?
GraphQL API를 개발하다 보면 N+1 문제를 해결하기 위해 DataLoader를 사용하게 됩니다. Query에서는 매우 효과적이지만, Mutation에서도 같은 방식으로 사용해도 될까요? 이 글에서는 DataLoader의 동작 원리를 이해하고, Mutation에서 사용 시 발생할 수 있는 문제점들을 살펴보겠습니다.
DataLoader란?
DataLoader는 Facebook에서 만든 배칭(Batching)과 캐싱(Caching) 유틸리티로, GraphQL의 N+1 문제를 해결하기 위해 사용됩니다.
N+1 문제 예시
query {
posts {
# 1번: 모든 posts 조회
id
title
author {
# N번: 각 post마다 author 조회
id
name
}
}
}DataLoader 없이 구현하면:
SELECT * FROM posts; -- 1번 쿼리
SELECT * FROM users WHERE id=1; -- post 1의 author
SELECT * FROM users WHERE id=2; -- post 2의 author
SELECT * FROM users WHERE id=1; -- post 3의 author (중복!)DataLoader 사용 시:
SELECT * FROM posts; -- 1번 쿼리
SELECT * FROM users WHERE id IN (1,2); -- 1번의 배치 쿼리DataLoader 동작 원리
DataLoader는 Node.js의 process.nextTick을 활용하여 같은 이벤트 루프 틱(tick) 내에서 발생한 모든 load() 호출을 모아서 하나의 배치로 실행합니다.
const userLoader = new DataLoader(async (userIds) => {
console.log('배치 실행:', userIds)
const users = await User.find({ _id: { $in: userIds } })
return userIds.map((id) => users.find((u) => u._id.equals(id)))
})
// 실행 과정
console.log('1. 시작')
userLoader.load('user-1').then((u) => console.log('4. User 1:', u.name))
userLoader.load('user-2').then((u) => console.log('5. User 2:', u.name))
userLoader.load('user-1').then((u) => console.log('6. User 1 (캐시):', u.name))
console.log('2. load() 호출 완료')
// 출력:
// 1. 시작
// 2. load() 호출 완료
// 배치 실행: ['user-1', 'user-2'] ← 중복 제거됨
// 4. User 1: Alice
// 5. User 2: Bob
// 6. User 1 (캐시): Alice핵심 메커니즘
- Request Queuing:
load()호출 시 즉시 실행하지 않고 큐에 추가 - Batch Execution: 현재 틱이 끝나면
process.nextTick()에서 배치 실행 - Caching: 결과를 캐시에 저장하여 중복 요청 방지
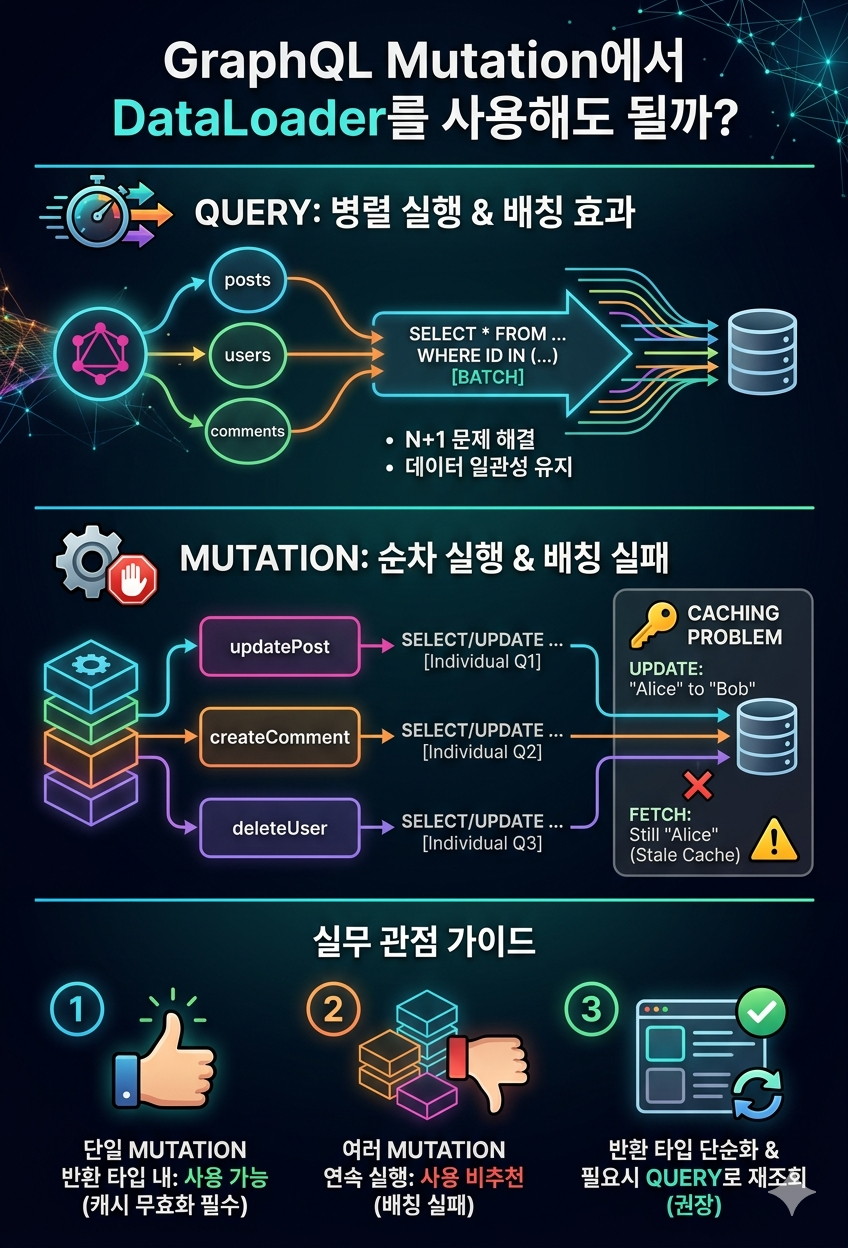
Query와 Mutation의 실행 방식 차이
Query: 병렬 실행
GraphQL Query는 같은 레벨의 필드들을 병렬로 실행합니다.
query {
post1: post(id: 1) {
author {
name
}
}
post2: post(id: 2) {
author {
name
}
}
post3: post(id: 3) {
author {
name
}
}
}실행 과정:
Tick 1: post1, post2, post3 resolver 동시 실행
Tick 2: author field resolver 모두 실행
├─ userLoader.load(user-1)
├─ userLoader.load(user-2)
└─ userLoader.load(user-1)
Tick 3: DataLoader 배치 실행
└─ SELECT * FROM users WHERE id IN (user-1, user-2)✅ 결과: 1번의 배치 쿼리로 완료
Mutation: 순차 실행
GraphQL 스펙에 따라 Mutation은 순차적으로 실행됩니다. 데이터 일관성을 보장하기 위한 의도적인 설계입니다.
mutation {
update1: updatePost(id: 1) {
author {
name
}
}
update2: updatePost(id: 2) {
author {
name
}
}
update3: updatePost(id: 3) {
author {
name
}
}
}실행 과정:
=== Mutation 1 실행 ===
Tick 1-2: updatePost(id: 1) 완료
Tick 3: author field resolver
└─ userLoader.load(user-1)
Tick 4: DataLoader 배치 실행
└─ SELECT * FROM users WHERE id = user-1
⏸️ Mutation 1이 완전히 끝날 때까지 대기
=== Mutation 2 실행 ===
Tick 5-6: updatePost(id: 2) 완료
Tick 7: author field resolver
└─ userLoader.load(user-2)
Tick 8: DataLoader 배치 실행
└─ SELECT * FROM users WHERE id = user-2
⏸️ 대기
=== Mutation 3 실행 ===
Tick 9-11: updatePost(id: 3) 완료, author 조회
└─ SELECT * FROM users WHERE id = user-1❌ 결과: 3번의 개별 쿼리 실행 (배칭 실패)
Mutation에서 DataLoader 사용 시 문제점
문제 1: 배칭 효과 없음
여러 Mutation을 연속으로 실행하면 각각이 완전히 끝난 후 다음이 시작되므로, field resolver들이 서로 다른 틱에서 실행됩니다. DataLoader의 배칭이 작동하지 않습니다.
// Mutation Resolver
const resolvers = {
Mutation: {
updatePosts: async (_, { ids }, { loaders }) => {
const results = []
// ❌ 순차 실행 - 배칭 안됨
for (const id of ids) {
const post = await Post.update(id)
const author = await loaders.userLoader.load(post.authorId)
results.push({ post, author })
}
return results
},
},
}문제 2: 캐시 무효화 (Stale Data)
더 심각한 문제는 캐시 무효화입니다. DataLoader는 요청당 하나의 인스턴스가 생성되고, 요청이 끝날 때까지 캐시를 유지합니다.
mutation {
# 1. Author를 "Alice"로 업데이트
updateAuthor1: updateAuthor(id: 1, name: "Alice") {
id
name # "Alice" 반환
}
# 2. Post 조회
getPost: post(id: 1) {
author {
id
name # ✅ 캐시에서 "Alice" 반환
}
}
# 3. 같은 Author를 "Bob"으로 다시 업데이트
updateAuthor2: updateAuthor(id: 1, name: "Bob") {
id
name # "Bob" 반환
}
# 4. 다시 Post 조회
getPost2: post(id: 1) {
author {
id
name # ❌ 캐시에서 "Alice" 반환! (DB는 "Bob")
}
}
}문제 발생 원인:
// DataLoader 내부 동작
class DataLoader {
constructor(batchLoadFn) {
this._cache = new Map()
}
load(key) {
// 캐시 확인
if (this._cache.has(key)) {
return Promise.resolve(this._cache.get(key)) // ⚠️ 캐시된 데이터 반환
}
// ... 배치에 추가 및 캐시 저장
}
}updateAuthor1이 완료되면서 author가 조회되고 캐시에 “Alice” 저장getPost의 author field resolver가 캐시에서 “Alice” 반환updateAuthor2가 DB의 author를 “Bob”으로 변경 (캐시는 모름!)getPost2의 author field resolver가 여전히 캐시에서 “Alice” 반환
그렇다면 Mutation에서는 절대 사용하면 안 될까?
✅ 허용되는 경우: 단일 Mutation의 반환 타입
단일 Mutation의 반환 타입 내부에서는 field resolver들이 같은 틱에서 실행되므로 DataLoader가 정상 작동합니다.
mutation {
createOrder(
items: [
{ productId: 1, quantity: 2 }
{ productId: 2, quantity: 1 }
{ productId: 3, quantity: 5 }
]
) {
id
items {
product {
name
price
} # ✅ 배칭 작동
seller {
name
} # ✅ 배칭 작동
}
}
}실행 과정:
Tick 1: createOrder resolver 완료
Tick 2: items field resolver 실행
Tick 3: product, seller field resolver 동시 실행
├─ productLoader.load(1)
├─ productLoader.load(2)
├─ productLoader.load(3)
├─ sellerLoader.load(s1)
└─ sellerLoader.load(s2)
Tick 4: DataLoader 배치 실행
├─ SELECT * FROM products WHERE id IN (1,2,3)
└─ SELECT * FROM sellers WHERE id IN (s1,s2)✅ 각 타입당 1번의 배치 쿼리로 완료
하지만 이 경우에도 캐시 무효화 문제는 여전히 존재합니다.
❌ 피해야 하는 경우: 여러 Mutation 연속 실행
mutation {
order1: createOrder(...) {
items { product { name } } # Batch 1
}
order2: createOrder(...) {
items { product { name } } # Batch 2 (별도 쿼리)
}
}이 경우 각 Mutation이 순차 실행되므로 배칭 효과가 없습니다.
해결 방법
방법 1: Mutation 요청에서 캐시 비활성화
import DataLoader from 'dataloader'
export function createContext({ req }) {
const query = req.body.query || ''
const isMutation = query.trim().startsWith('mutation')
return {
loaders: {
userLoader: new DataLoader(
async (ids) => {
/* ... */
},
{
cache: !isMutation, // Mutation이면 캐시 비활성화
},
),
},
}
}장점: 간단하고 확실한 해결책
단점: Mutation의 반환 타입에서도 캐싱 효과를 받지 못함
방법 2: 명시적 캐시 무효화
const resolvers = {
Mutation: {
updateUser: async (_, { id, input }, { loaders }) => {
const user = await User.findByIdAndUpdate(id, input, { new: true })
// ✅ 변경된 엔티티의 캐시 제거
loaders.userLoader.clear(id)
// 또는 관련된 모든 캐시 제거
// loaders.userLoader.clearAll();
return user
},
deleteUser: async (_, { id }, { loaders }) => {
await User.findByIdAndDelete(id)
loaders.userLoader.clear(id)
return { success: true }
},
},
}장점: 세밀한 제어 가능
단점: 모든 Mutation에서 수동으로 관리해야 하며, 실수하기 쉬움
방법 3: 반환 타입 단순화 (권장)
// ❌ 피해야 할 패턴
const typeDefs = gql`
type Mutation {
updateUser(id: ID!, input: UserInput!): User
}
type User {
id: ID!
name: String!
email: String!
posts: [Post!]! # 복잡한 중첩 타입
friends: [User!]! # 복잡한 중첩 타입
}
`
// ✅ 권장 패턴
const typeDefs = gql`
type Mutation {
updateUser(id: ID!, input: UserInput!): UpdateUserPayload!
}
type UpdateUserPayload {
success: Boolean!
userId: ID
message: String
}
`클라이언트에서 최신 데이터가 필요하면 별도 Query로 재조회:
# Mutation 실행
mutation {
updateUser(id: "1", input: { name: "Alice" }) {
success
userId
}
}
# 최신 데이터 조회
query {
user(id: "1") {
id
name
email
posts {
id
title
}
}
}장점:
- Mutation과 Query의 책임 분리
- 캐시 문제 원천 차단
- 명확한 API 설계
단점:
- 클라이언트에서 2번의 요청 필요
방법 4: 여러 Mutation을 단일 Mutation으로 통합
// ❌ 배칭 안됨
mutation {
order1: createOrder(userId: 1, items: [...]) { ... }
order2: createOrder(userId: 2, items: [...]) { ... }
order3: createOrder(userId: 3, items: [...]) { ... }
}
// ✅ 배칭됨
mutation {
createOrders(orders: [
{ userId: 1, items: [...] },
{ userId: 2, items: [...] },
{ userId: 3, items: [...] }
]) {
orders {
id
items { product { name } } # 모두 같은 배치에서 처리
}
}
}실무 권장 사항
1. Query에서는 적극 활용
// ✅ Query는 DataLoader의 최적 사용처
const resolvers = {
Query: {
posts: () => Post.find(),
},
Post: {
author: (post, _, { loaders }) => {
return loaders.userLoader.load(post.authorId)
},
comments: (post, _, { loaders }) => {
return loaders.commentsByPostIdLoader.load(post.id)
},
},
}2. Mutation에서는 신중하게 사용
// ⚠️ Mutation에서는 캐시 관리 필수
const resolvers = {
Mutation: {
updatePost: async (_, { id, input }, { loaders }) => {
const post = await Post.findByIdAndUpdate(id, input)
// 변경된 데이터 캐시 무효화
loaders.postLoader.clear(id)
if (input.authorId) {
loaders.userLoader.clear(input.authorId)
}
return post
},
},
}3. 반환 타입은 단순하게
// ✅ 단순한 Payload 타입 사용
type MutationPayload {
success: Boolean!
message: String
id: ID
}결론
DataLoader는 읽기 작업(Query)에 최적화된 도구입니다. Query의 field resolver들이 병렬로 실행되면서 자연스럽게 배칭과 캐싱의 이점을 누릴 수 있도록 설계되었습니다.
Mutation에서 사용하면:
- 배칭 효과는 제한적 (순차 실행으로 인해)
- 캐시 관리가 복잡 (데이터 일관성 문제)
- 예상치 못한 버그 발생 가능 (stale data)
따라서:
- 여러 Mutation을 연속 실행하는 경우: 배칭 효과 없으므로 사용 지양
- 단일 Mutation의 복잡한 반환 타입: 사용 가능하지만 캐시 무효화 필수
- 권장 패턴: Mutation은 단순한 결과만 반환하고, 클라이언트가 필요시 별도 Query로 최신 데이터 조회
DataLoader를 Mutation에서 사용할지는 “취향”의 문제가 아니라, 아키텍처와 데이터 일관성을 고려한 신중한 설계 결정이 필요한 영역입니다.
참고 자료
이 저작물은 크리에이티브 커먼즈 저작자표시-비영리-동일조건변경허락 4.0 국제 라이선스 에 따라 이용할 수 있습니다.
Comments
Related Posts

GitHub Actions로 PR 작성자를 자동으로 Assignee에 할당하기
개요 GitHub에서 Pull Request(PR)를 생성할 때마다 매번 수동으로 Assignee를 지정하는 것이 번거로우신가요? GitHub Actions을 활용하면 PR을 생성…

Javascript 내장함수를 이용한 숫자/날짜의 현지화
이전에 포스팅했던 글 중에 javascript comma and uncomma 라는 글이 있다. 한국에서 숫자를 표시할 때 보통 셋째 자리에서 콤마를 찍어주는데 화면을 구성할 때…

<img> 태그의 주소 값으로 # 은 사용해서 안된다.
이미 오래된 내용이지만 아직도 유효하기에 작은 팁으로써 아래의 글을 남긴다. 제목에 나온대로 태그의 값으로 #은 입력 하면 안된다. 왜 안되는지 결론부터 이야기 하면 서버에…